

Working with Git Worktrees - Part 2
Chris Di Carlo • March 26, 2022
In my last post, I mentioned what a boon the combination of leveraging Git worktrees and my VSCode extension Switch Git Worktree has made to my workflow. The last missing piece was how to speed up getting a new worktree scaffolded out so I can quickly get working on the important bits, namely the code. I aluded to some scripts I had written; over the last couple of weeks I've significantly improved and consolidated those scripts to the point where I'm pretty happy.
Getting a new worktree for a Laravel application up and running entails a number of steps, e.g. (and this is not a comprehensive list!):
- create the .env files,
- install Composer dependencies
- install NPM dependencies
- run NPM build scripts
- create the database(s)
- set up and secure the Valet site
- potentially restore a database backup
Whew! That's a lot of steps to get it set up! And as I tweaked and improved my scaffolding setup, I kept coming across little nuanced things I kept needing to do manually and slowly integrated them.
And let's not forget the cleanup - when I was done with a worktree, I also needed to drop the databases, cleanup the Valet configs, etc. Again, tedious steps and I was having to keep doing them. And nothing makes my skin crawl more than having to constantly, manually, perform tasks that I know can be automated. And so, drumroll please...
The end results of this adventure are 2 bash functions, scaffold and teardown. Yeah, original names, right? :)
The scaffold Function
First off, I'll show the help for scaffold - as I have a couple of different setups on different devices, I needed to be able to tweak how it worked and command-line arguments seemed the best way to do that:
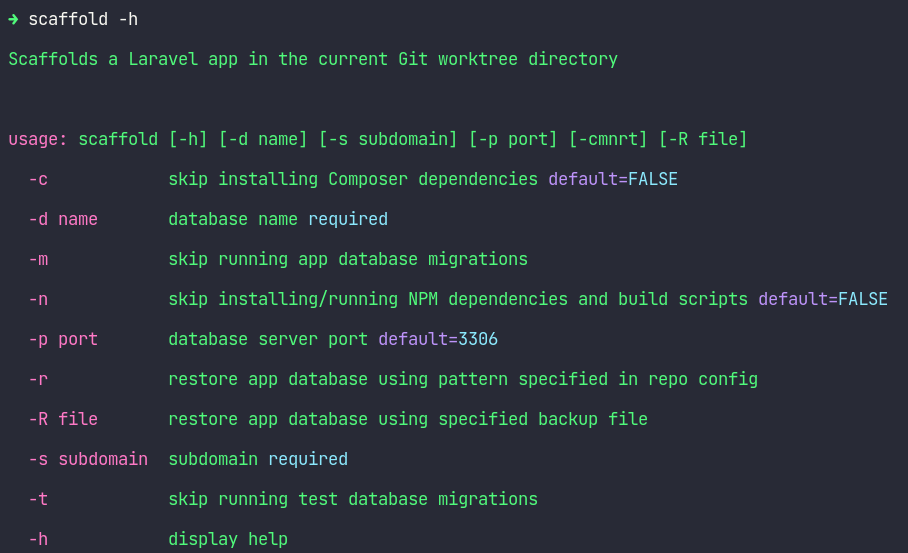
Most of those settings are probably self-explanatory but I want to call out the -r option - this lets me have a glob in an .env file in the root bare Git repository with a BACKUP_FILE key. This key is used to automatically find the newest backup file to do the restore. More on database restores later.
It's definitely not the most elegant script and I'm sure someone much more knowledgeable could improve it but hey, it works and I'm happy! I'll break down the function in chunks and detail what each part does. One thing to note - I'm going to remove most of the echo statements to make it easier to read unless it's core to the explanation.
Pre-checks
After the prototypical command-line argument parsing stuff at the beginning of the function, the first thing it does is check to make sure the current working directing is in fact a Git repository. I do that by simply checking for the existence of the .git file for the worktree:
if [ ! -f "./.git" ]; then
echo "This is not a git repository, aborting...";
return;
fi
Next, it checks to make sure the database name and subdomain options were passed in; if not, it displays the function help.
We're Good, Let's Roll!
Now that the basics are handled and we know we have the bare minimum we need to work with, the real fun begins!
Folder Creation
First up, I create the missing storage folders (so that Laravel doesn't throw a fit later) and the .vscode directory:
mkdir -p storage/framework/{cache,sessions,views} .vscode
Environment Files
Next up, I copy the .env.example to .env and .env.testing (I have .env.testing in my gitignore file because tend to have a specific config):
cp -n .env.example .env
cp -n .env.example .env.testing
The -n option just makes sure I don't clobber an existing file if for some reason I already had one in the tree.
Now comes the interesting part - I proceed to update the .env and .env.testing database config based on the command-line arguments that were passed in. I used sed to update the DB_PORT, DB_DATABASE, DB_USERNAME, and DB_PASSWORD keys in each environment file.
sed -i "s/\(^DB_PORT=.*\)/DB_PORT=$dbPort/g" .env
sed -i "s/\(^DB_DATABASE=.*\)/DB_DATABASE=$database/g" .env
sed -i "s/\(^DB_USERNAME=.*\)/DB_USERNAME=root/g" .env
sed -i "s/\(^DB_PASSWORD=.*\)/DB_PASSWORD=/g" .env
sed -i "s/\(^DB_PORT=.*\)/DB_PORT=3307/g" .env.testing
sed -i "s/\(^DB_DATABASE=.*\)/DB_DATABASE=$database/g" .env.testing
sed -i "s/\(^DB_USERNAME=.*\)/DB_USERNAME=root/g" .env.testing
sed -i "s/\(^DB_PASSWORD=.*\)/DB_PASSWORD=/g" .env.testing
I keep my testing database server on a different port, hence the change in port number for the testing environment.
Next, I look in the bare repository's root directory for the existence of a .env file. I usually use the excellent error tracker HoneyBadger and I also use Slack to notify others when deployments happen; both require keys to be set in the local .env files. By adding them to a file at the root, I can grab them and update the worktree's values:
sed -i "s/\(^HONEYBADGER_API_KEY=.*\)/HONEYBADGER_API_KEY=$(awk -F "=" '/^HONEYBADGER_API_KEY/{print $NF}' ../.env)/g" .env
sed -i "s,\(^SLACK_DEPLOY_WEBHOOK_URL=.*\),SLACK_DEPLOY_WEBHOOK_URL=$(awk -F "=" '/^SLACK_DEPLOY_WEBHOOK_URL/{print $NF}' ../.env),g" .env
VSCode Launch Config
Next I create a VSCode launch configuration for use with XDebug:
cat << EOF > ./.vscode/launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Listen for Xdebug",
"type": "php",
"request": "launch",
"port": 9003,
"xdebugSettings": {
"max_children": 999,
"max_depth": 3,
}
},
]
}
EOF
Create Application Database
Next I create the main application database by grabbing the database configuration from the .env file. I used awk for this job:
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env) -uroot -e "CREATE DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;" &>/dev/null
Composer Dependencies
Now I check if the option to skip the Composer installation was set - BUT - if there's no vendor directory, I echo out a message and then proceed to ignore the option.
if [ "$skipComposer" = true ]; then
if [ ! -d "vendor" ]; then
skipComposer=false
fi
fi
if [ "$skipComposer" = false ]; then
XDEBUG_MODE=off composer install --quiet
else
echo -e "${PURPLE}Skipping installation of ${BLUE}Composer dependencies${GREEN}..."
fi
Generate Application Key
Next, I generate an app key:
XDEBUG_MODE=off php artisan key:generate --quiet
The XDEBUG_MODE=off is just there to force XDebug to off just in case I've got it enabled. It speeds things up a bit.
Create Testing and Parallel Testing Databases
Next, I create the testing databases:
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env.testing) -uroot -e "CREATE DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env.testing) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;" &>/dev/nul
if [ "$skipTestMigrations" = false ]; then
XDEBUG_MODE=off php artisan migrate:fresh --env=testing --seed --quiet
else
echo -e "${PURPLE}Skipping running of ${BLUE}test database migrations${GREEN}..."
fi
for i in 1 2 3 4
do
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env.testing) -uroot -e "DROP DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env.testing)_$i;" &>/dev/null
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env.testing) -uroot -e "CREATE DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env.testing)_$i CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;" &>/
mysqldump --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env.testing) -uroot $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env.testing) | mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env
done
This section maybe bears a bit of explanation: first, I create the normal test database. Then I check if the option to skip the test migrations was set - if not, I run the migrations and seed the database for the testing environment. I loop 4 times (because my workstation has 4 cores) to drop (if it exists) and create each numbered database used for parallel testing. After creating each parallel testing database, I restore a copy of the normal testing database so they are in sync.
NPM Dependencies and Build Scripts
Next, in the same vein as Composer, for the NPM dependency installation I check for the skip option and act accordingly:
if [ "$skipNpm" = true ]; then
if [ ! -d "node_modules" ]; then
skipNpm=false
fi
fi
if [ "$skipNpm" = false ]; then
npm install --quiet &>/dev/null
npm run dev &>/dev/null
else
echo -e "${PURPLE}Skipping installation of ${BLUE}NPM dependencies ${PURPLE}and running ${BLUE}npm dev ${PURPLE}build script..."
fi
APP_URL and Valet config
Next, I update the APP_URL in the .env file and configure the Valet site:
folder=$(pwd)
parent=$(dirname "$folder")
rootDomain="$(basename $parent)"
fullDomain="https://$subdomain.$rootDomain.test"
sed -i "s,\(^APP_URL=.*\),APP_URL=$fullDomain,g" .env
valet link --quiet "$subdomain"."$rootDomain"
valet secure --quiet "$subdomain"."$rootDomain"
Application Database Restore
Now comes some gnarly code - it's not pretty, it's not elegant, it's not optimized. But it does the job.
To automatically restore the app database during the scaffolding, I wanted the option to either pass in a specific file or have the script look somewhere and just grab the most recent file. To that end, there are -r and -R options. The former does an automatic lookup, the latter requires you to provide the path to a MySQL dump.
if [ "$restore" = true ]; then
# Determine the backup file
if [ -z "$backupFile" ]; then
backupFilePattern=$(awk -F "=" '/^BACKUP_FILE/{print $NF}' ../.env);
if [ -z $backupFilePattern ]; then
restore=false;
else
backupFile=`ls "$backupFilePattern"* | sort -r | head -1`
if [[ ! -f "$backupFile" ]]; then
restore=false;
else
echo -e "${GREEN}Found backup file ${BLUE}$backupFile${GREEN}..."
fi
fi
else
if [ ! -f "$backupFile" ]; then
restore=false;
fi
fi
if [ "$restore" = true ]; then
XDEBUG_MODE=off php artisan db:wipe --quiet
fileSize=`stat --printf="%s" $backupFile`
pv --size $fileSize $backupFile | mysql -h 127.0.0.1 -P $dbPort -uroot $database
if [ "$skipAppMigrations" = false ]; then
XDEBUG_MODE=off php artisan migrate --quiet
else
echo -e "${PURPLE}Skipping running of ${BLUE}app database migrations${GREEN}..."
fi
else
if [ "$skipAppMigrations" = false ]; then
XDEBUG_MODE=off php artisan migrate:fresh --seed --quiet
else
echo -e "${PURPLE}Skipping running of ${BLUE}app database migrations${GREEN}..."
fi
fi
Again, this one requires some explanation.
First, I check if a restore was even requested: if not, I check if the option to skip migrations was set and run the migrations and seed, if needed. That's the simplest path.
The more complicated path first checks if a backup file was passed in via the -R option and checks if it exists; if it does not, it then proceeds to check the root .env file for a BACKUP_FILE key and if it doesn't exist, it aborts the database restore. If no backup file was specified but the BACKUP_FILE key exists, it gets the latest backup file by filename (I always save my backups something like appname_prod_
If everything is still good to perform the restore, I first wipe the application database (just in case), and then restore the backup. I use the stat and pv commands to provide visual feedback of the restore progress. It then runs the migrations unless the user opted to skip; it does not however, run the seeders as the expectation is that the database backup has already had them run.
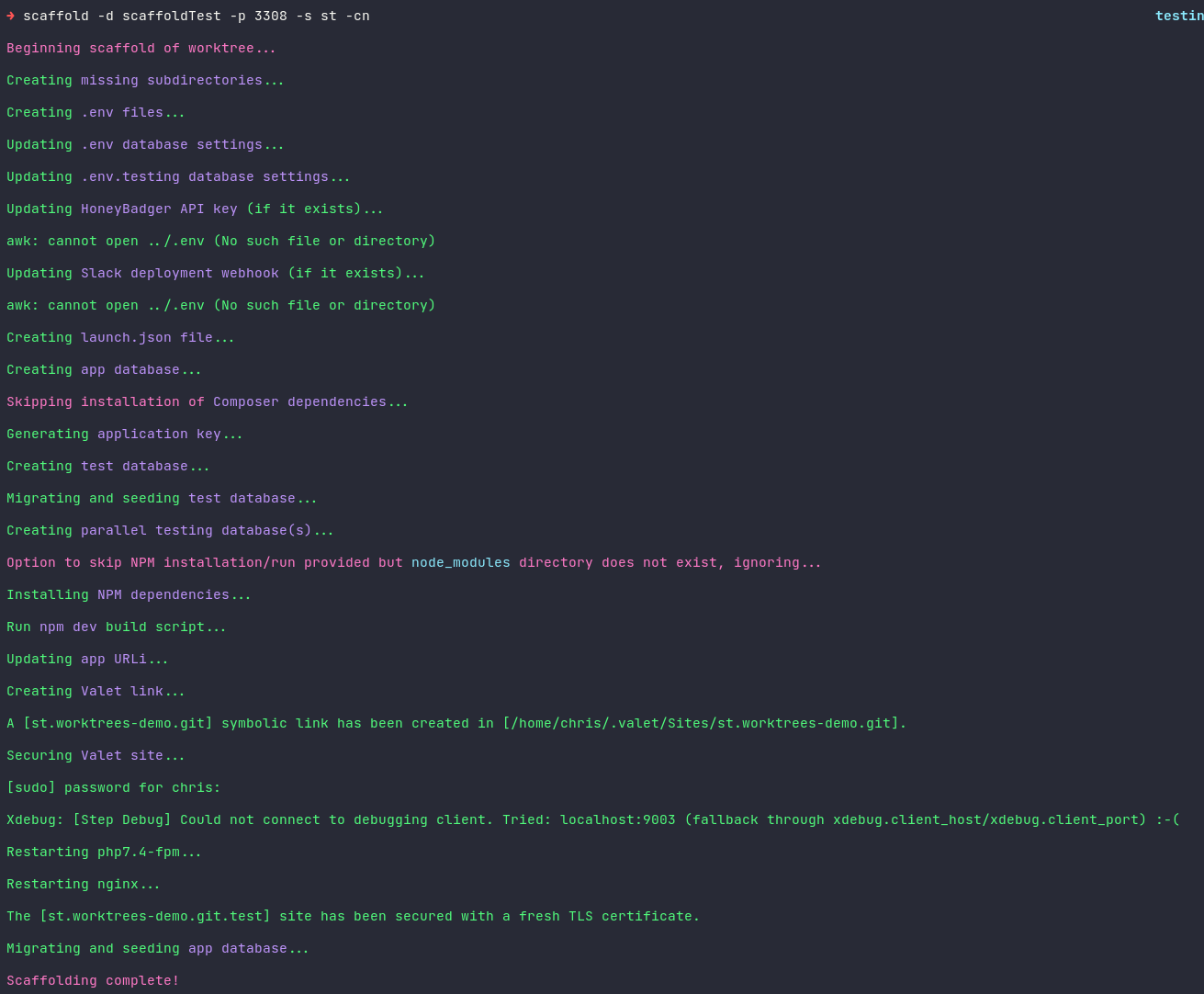
After all that, here's a sample run:
The teardown Function
This function is downright quaint by comparison so I'm just going to show the whole thing and provide some explanation.
if [ ! -f "./.git" ]; then
echo "${GREEN}This is not a git repository, aborting...";
return;
fi
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env) -uroot -e "DROP DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env);"
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env.testing) -uroot -e "DROP DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env.testing);"
for i in 1 2 3 4
do
mysql --host=127.0.0.1 --port=$(awk -F "=" '/^DB_PORT/{print $NF}' .env.testing) -uroot -e "DROP DATABASE $(awk -F "=" '/^DB_DATABASE/{print $NF}\' .env.testing)_$i;"
done
valet unsecure $(awk -F "/." '/^APP_URL=https:\/\//{print $2}' .env | sed 's/^[^ ]* \|\.test*//g')
valet unlink $(awk -F "/." '/^APP_URL=https:\/\//{print $2}' .env | sed 's/^[^ ]* \|\.test*//g')
git worktree remove --force $(pwd)
folder=$(pwd)
parent=$(dirname "$folder")
cd "$parent"
echo "${PURPLE}Teardown complete!";
I'll detail each major step:
- Check if we're in a Git repository; abort if not
- Drop the application (database based on the settings in the .env file)
- Drop the test database (based on the settings in the .env.testing file)
- Drop each of the parallel testing databases (based on the settings in the .env.testing file)
- Remove the Valet configuration
- Remove the Git worktree
- And finally, just move back to the parent directory
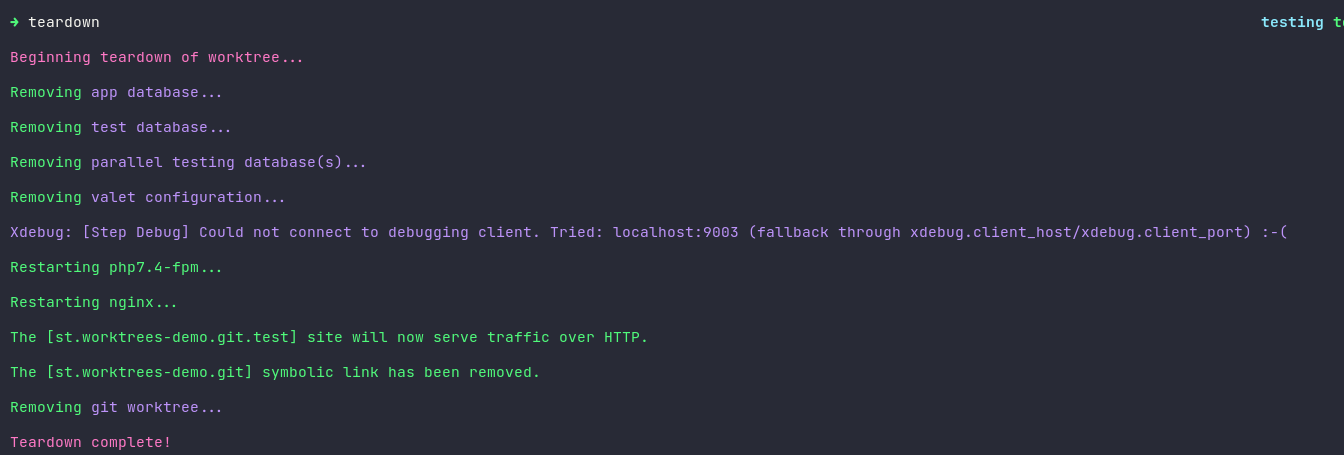
Here's a sample run of this function:
Conclusion
I've been using this script now for a couple of weeks and it's improved my developer experience immeasurably. There's still some minor tweaks I want to make, like some additional validation around the root .env file and keys. I would also love to get rid of that stupid Xdebug error that sometimes pop up when running some of the Valet commands (you can see them in the sample run images) but I've yet to get that to work. Minor thing, just throws off the aesthetics of the console output!
If you have any thoughts or feedback about any of this stuff, feel free to reach out to me on Twitter at @chris_di_carlo.
Happy coding! Cheers